autoware_traffic_light_classifier#
Purpose#
autoware_traffic_light_classifier is a package for classifying traffic light labels using cropped image around a traffic light. This package has two classifier models: cnn_classifier and hsv_classifier.
Inner-workings / Algorithms#
If height and width of ~/input/rois is 0, color, shape, and confidence of ~/output/traffic_signals become UNKNOWN, CIRCLE, and 0.0.
If ~/input/rois is judged as backlight, color, shape, and confidence of ~/output/traffic_signals become UNKNOWN, UNKNOWN, and 0.0.
cnn_classifier#
Traffic light labels are classified by EfficientNet-b1 or MobileNet-v2.
We trained classifiers for vehicular signals and pedestrian signals separately.
For vehicular signals, a total of 83400 (58600 for training, 14800 for evaluation and 10000 for test) TIER IV internal images of Japanese traffic lights were used for fine-tuning.
| Name | Input Size | Test Accuracy |
|---|---|---|
| EfficientNet-b1 | 128 x 128 | 99.76% |
| MobileNet-v2 | 224 x 224 | 99.81% |
For pedestrian signals, a total of 21199 (17860 for training, 2114 for evaluation and 1225 for test) TIER IV internal images of Japanese traffic lights were used for fine-tuning.
The information of the models is listed here:
| Name | Input Size | Test Accuracy |
|---|---|---|
| EfficientNet-b1 | 128 x 128 | 97.89% |
| MobileNet-v2 | 224 x 224 | 99.10% |
hsv_classifier#
Traffic light colors (green, yellow and red) are classified in HSV model.
About Label#
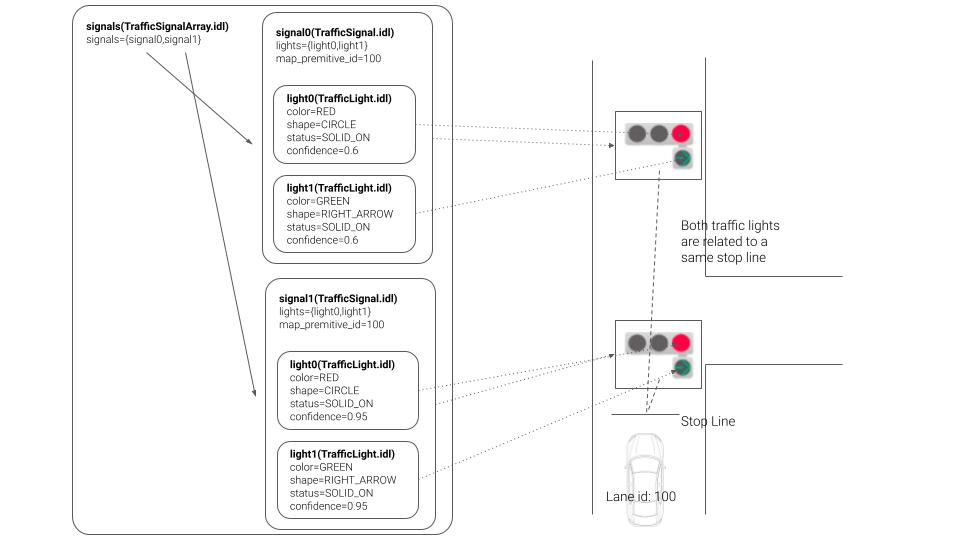
The message type is designed to comply with the unified road signs proposed at the Vienna Convention. This idea has been also proposed in Autoware.Auto.
There are rules for naming labels that nodes receive. One traffic light is represented by the following character string separated by commas. color1-shape1, color2-shape2 .
For example, the simple red and red cross traffic light label must be expressed as "red-circle, red-cross".
These colors and shapes are assigned to the message as follows:
Inputs / Outputs#
Input#
| Name | Type | Description |
|---|---|---|
~/input/image |
sensor_msgs::msg::Image |
input image |
~/input/rois |
tier4_perception_msgs::msg::TrafficLightRoiArray |
rois of traffic lights |
Output#
| Name | Type | Description |
|---|---|---|
~/output/traffic_signals |
tier4_perception_msgs::msg::TrafficLightArray |
classified signals |
~/output/debug/image |
sensor_msgs::msg::Image |
image for debugging |
Parameters#
Node Parameters#
car_traffic_light_classifier#
| Name | Type | Description | Default | Range |
|---|---|---|---|---|
| approximate_sync | boolean | Enable or disable approximate synchronization. | False | N/A |
| precision | string | Precision used for traffic light classifier inference. Valid values: [fp32, fp16, int8]. | fp16 | N/A |
| mean | array | Mean values used for input normalization [R, G, B]. | [123.675, 116.28, 103.53] | N/A |
| std | array | Standard deviation values used for input normalization [R, G, B]. | [58.395, 57.12, 57.375] | N/A |
| over_exposure_threshold | float | If the intensity get grater than this overwrite with UNKNOWN in corresponding RoI. Note that, if the value is much higher, the node only overwrites in the over exposure situations. Therefore, If you wouldn't like to use this feature set this value to 1.0. The value can be [0.0, 1.0]. The confidence of overwritten signal is set to 0.0. |
0.85 | N/A |
| under_exposure_threshold | float | If the intensity get lesser than this overwrite with UNKNOWN in corresponding RoI. Note that, if the value is much lesser, the node only overwrites in the under exposure situations. Therefore, If you wouldn't like to use this feature set this value to -1.0. The confidence of overwritten signal is set to 0.0. |
-0.83 | N/A |
| score_threshold | float | Minimum detection score for LampRecognizer/CNN outputs (objectness * class probability where applicable). | 0.2 | N/A |
| nms_threshold | float | IoU threshold for non-maximum suppression after decoding detections (LampRecognizer). | 0.2 | N/A |
| max_batch_size | integer | Maximum batch size for TensorRT inference (CNN / LampRecognizer). | 64 | N/A |
| classifier_type | integer | Type of classifier used. {0: hsv_filter (rule-based), 1: cnn (single-crop), 2: LampRecognizer (cnn per lamp). | 1 | N/A |
| traffic_light_type | integer | Type of traffic light to classify. {0: car, 1: pedestrian}. | 0 | N/A |
| regression_arch.num_anchors | integer | Number of anchor boxes per grid cell for LampRecognizer decode (must match model). Nested under regression_arch in YAML. | 3 | N/A |
| regression_arch.chans_per_anchor | integer | Output channels per anchor for LampRecognizer (full head width before grid flatten). | 16 | N/A |
| regression_arch.x_index | integer | Channel index of bbox x (within each anchor slice) for LampRecognizer. | 0 | N/A |
| regression_arch.y_index | integer | Channel index of bbox y (within each anchor slice) for LampRecognizer. | 1 | N/A |
| regression_arch.w_index | integer | Channel index of bbox w (within each anchor slice) for LampRecognizer. | 2 | N/A |
| regression_arch.h_index | integer | Channel index of bbox h (within each anchor slice) for LampRecognizer. | 3 | N/A |
| regression_arch.obj_index | integer | Channel index of objectness for LampRecognizer. | 4 | N/A |
| regression_arch.color_start | integer | First channel index of color logits (length regression_arch.num_colors) for LampRecognizer. | 5 | N/A |
| regression_arch.type_start | integer | First channel index of shape/type logits (length regression_arch.num_types) for LampRecognizer. | 8 | N/A |
| regression_arch.num_types | integer | Number of shape/type classes for LampRecognizer. | 6 | N/A |
| regression_arch.num_colors | integer | Number of color classes for LampRecognizer. | 3 | N/A |
| regression_arch.cos_index | integer | Channel index of cos(angle) for LampRecognizer. | 14 | N/A |
| regression_arch.sin_index | integer | Channel index of sin(angle) for LampRecognizer. | 15 | N/A |
| regression_arch.scale_x_y | float | YOLO-style center decode scale for x/y (with offset derived as 0.5*(scale-1)). | 2.0 | N/A |
| regression_arch.anchors | array | Anchor widths and heights interleaved [w0,h0,w1,h1,...]; length must be 2*regression_arch.num_anchors. | [7.0, 7.0, 14.0, 14.0, 42.0, 42.0] | N/A |
pedestrian_traffic_light_classifier#
| Name | Type | Description | Default | Range |
|---|---|---|---|---|
| approximate_sync | boolean | Enable or disable approximate synchronization. | False | N/A |
| precision | string | Precision used for traffic light classifier inference. Valid values: [fp32, fp16, int8]. | fp16 | N/A |
| mean | array | Mean values used for input normalization [R, G, B]. | [123.675, 116.28, 103.53] | N/A |
| std | array | Standard deviation values used for input normalization [R, G, B]. | [58.395, 57.12, 57.375] | N/A |
| over_exposure_threshold | float | If the intensity get grater than this overwrite with UNKNOWN in corresponding RoI. Note that, if the value is much higher, the node only overwrites in the over exposure situations. Therefore, If you wouldn't like to use this feature set this value to 1.0. The value can be [0.0, 1.0]. The confidence of overwritten signal is set to 0.0. |
0.85 | N/A |
| under_exposure_threshold | float | If the intensity get lesser than this overwrite with UNKNOWN in corresponding RoI. Note that, if the value is much lesser, the node only overwrites in the under exposure situations. Therefore, If you wouldn't like to use this feature set this value to -1.0. The confidence of overwritten signal is set to 0.0. |
-0.83 | N/A |
| score_threshold | float | Minimum detection score for LampRecognizer/CNN outputs (objectness * class probability where applicable). | 0.2 | N/A |
| nms_threshold | float | IoU threshold for non-maximum suppression after decoding detections (LampRecognizer). | 0.2 | N/A |
| max_batch_size | integer | Maximum batch size for TensorRT inference (CNN / LampRecognizer). | 64 | N/A |
| classifier_type | integer | Type of classifier used. {0: hsv_filter (rule-based), 1: cnn (single-crop), 2: LampRecognizer (cnn per lamp). | 1 | N/A |
| traffic_light_type | integer | Type of traffic light to classify. {0: car, 1: pedestrian}. | 1 | N/A |
| regression_arch.num_anchors | integer | Number of anchor boxes per grid cell for LampRecognizer decode (must match model). Nested under regression_arch in YAML. | 3 | N/A |
| regression_arch.chans_per_anchor | integer | Output channels per anchor for LampRecognizer (full head width before grid flatten). | 16 | N/A |
| regression_arch.x_index | integer | Channel index of bbox x (within each anchor slice) for LampRecognizer. | 0 | N/A |
| regression_arch.y_index | integer | Channel index of bbox y (within each anchor slice) for LampRecognizer. | 1 | N/A |
| regression_arch.w_index | integer | Channel index of bbox w (within each anchor slice) for LampRecognizer. | 2 | N/A |
| regression_arch.h_index | integer | Channel index of bbox h (within each anchor slice) for LampRecognizer. | 3 | N/A |
| regression_arch.obj_index | integer | Channel index of objectness for LampRecognizer. | 4 | N/A |
| regression_arch.color_start | integer | First channel index of color logits (length regression_arch.num_colors) for LampRecognizer. | 5 | N/A |
| regression_arch.type_start | integer | First channel index of shape/type logits (length regression_arch.num_types) for LampRecognizer. | 8 | N/A |
| regression_arch.num_types | integer | Number of shape/type classes for LampRecognizer. | 6 | N/A |
| regression_arch.num_colors | integer | Number of color classes for LampRecognizer. | 3 | N/A |
| regression_arch.cos_index | integer | Channel index of cos(angle) for LampRecognizer. | 14 | N/A |
| regression_arch.sin_index | integer | Channel index of sin(angle) for LampRecognizer. | 15 | N/A |
| regression_arch.scale_x_y | float | YOLO-style center decode scale for x/y (with offset derived as 0.5*(scale-1)). | 2.0 | N/A |
| regression_arch.anchors | array | Anchor widths and heights interleaved [w0,h0,w1,h1,...]; length must be 2*regression_arch.num_anchors. | [7.0, 7.0, 14.0, 14.0, 42.0, 42.0] | N/A |
Core Parameters#
cnn_classifier#
Including this section
hsv_classifier#
| Name | Type | Description |
|---|---|---|
green_min_h |
int | the minimum hue of green color |
green_min_s |
int | the minimum saturation of green color |
green_min_v |
int | the minimum value (brightness) of green color |
green_max_h |
int | the maximum hue of green color |
green_max_s |
int | the maximum saturation of green color |
green_max_v |
int | the maximum value (brightness) of green color |
yellow_min_h |
int | the minimum hue of yellow color |
yellow_min_s |
int | the minimum saturation of yellow color |
yellow_min_v |
int | the minimum value (brightness) of yellow color |
yellow_max_h |
int | the maximum hue of yellow color |
yellow_max_s |
int | the maximum saturation of yellow color |
yellow_max_v |
int | the maximum value (brightness) of yellow color |
red_min_h |
int | the minimum hue of red color |
red_min_s |
int | the minimum saturation of red color |
red_min_v |
int | the minimum value (brightness) of red color |
red_max_h |
int | the maximum hue of red color |
red_max_s |
int | the maximum saturation of red color |
red_max_v |
int | the maximum value (brightness) of red color |
Training Traffic Light Classifier Model#
Overview#
This guide provides detailed instructions on training a traffic light classifier model using the mmlab/mmpretrain repository and deploying it using mmlab/mmdeploy. If you wish to create a custom traffic light classifier model with your own dataset, please follow the steps outlined below.
Data Preparation#
Use Sample Dataset#
Autoware offers a sample dataset that illustrates the training procedures for traffic light classification. This dataset comprises 1045 images categorized into red, green, and yellow labels. To utilize this sample dataset, please download it from link and extract it to a designated folder of your choice.
Use Your Custom Dataset#
To train a traffic light classifier, adopt a structured subfolder format where each subfolder represents a distinct class. Below is an illustrative dataset structure example;
```python DATASET_ROOT ├── TRAIN │ ├── RED │ │ ├── 001.png │ │ ├── 002.png │ │ └── ... │ │ │ ├── GREEN │ │ ├── 001.png │ │ ├── 002.png │ │ └──... │ │ │ ├── YELLOW │ │ ├── 001.png │ │ ├── 002.png │ │ └──... │ └── ... │ ├── VAL │ └──... │ │ └── TEST └── ...
```
Installation#
Prerequisites#
Step 1. Download and install Miniconda from the official website.
Step 2. Create a conda virtual environment and activate it
bash
conda create --name tl-classifier python=3.8 -y
conda activate tl-classifier
Step 3. Install PyTorch
Please ensure you have PyTorch installed, compatible with CUDA 11.6, as it is a requirement for current Autoware
bash
conda install pytorch==1.13.1 torchvision==0.14.1 pytorch-cuda=11.6 -c pytorch -c nvidia
Install mmlab/mmpretrain#
Step 1. Install mmpretrain from source
bash
cd ~/
git clone https://github.com/open-mmlab/mmpretrain.git
cd mmpretrain
pip install -U openmim && mim install -e .
Training#
MMPretrain offers a training script that is controlled through a configuration file. Leveraging an inheritance design pattern, you can effortlessly tailor the training script using Python files as configuration files.
In the example, we demonstrate the training steps on the MobileNetV2 model, but you have the flexibility to employ alternative classification models such as EfficientNetV2, EfficientNetV3, ResNet, and more.
Create a config file#
Generate a configuration file for your preferred model within the configs folder
bash
touch ~/mmpretrain/configs/mobilenet_v2/mobilenet-v2_8xb32_custom.py
Open the configuration file in your preferred text editor and make a copy of the provided content. Adjust the data_root variable to match the path of your dataset. You are welcome to customize the configuration parameters for the model, dataset, and scheduler to suit your preferences
```python
Inherit model, schedule and default_runtime from base model#
base = [ '../base/models/mobilenet_v2_1x.py', '../base/schedules/imagenet_bs256_epochstep.py', '../base/default_runtime.py' ]
Set the number of classes to the model#
You can also change other model parameters here#
For detailed descriptions of model parameters, please refer to link below#
(Customize model)[https://mmpretrain.readthedocs.io/en/latest/advanced_guides/modules.html]#
model = dict(head=dict(num_classes=3, topk=(1, 3)))
Set max epochs and validation interval#
train_cfg = dict(by_epoch=True, max_epochs=50, val_interval=5)
Set optimizer and lr scheduler#
optim_wrapper = dict( optimizer=dict(type='SGD', lr=0.001, momentum=0.9)) param_scheduler = dict(type='StepLR', by_epoch=True, step_size=1, gamma=0.98)
dataset_type = 'CustomDataset' data_root = "/PATH/OF/YOUR/DATASET"
Customize data preprocessing and dataloader pipeline for training set#
These parameters calculated for the sample dataset#
data_preprocessor = dict( mean=[0.2888 * 256, 0.2570 * 256, 0.2329 * 256], std=[0.2106 * 256, 0.2037 * 256, 0.1864 * 256], num_classes=3, to_rgb=True, )
Customize data preprocessing and dataloader pipeline for train set#
For detailed descriptions of data pipeline, please refer to link below#
(Customize data pipeline)[https://mmpretrain.readthedocs.io/en/latest/advanced_guides/pipeline.html]#
train_pipeline = [ dict(type='LoadImageFromFile'), dict(type='Resize', scale=224), dict(type='RandomFlip', prob=0.5, direction='horizontal'), dict(type='PackInputs'), ] train_dataloader = dict( dataset=dict( type=dataset_type, data_root=data_root, ann_file='', data_prefix='train', with_label=True, pipeline=train_pipeline, ), num_workers=8, batch_size=32, sampler=dict(type='DefaultSampler', shuffle=True) )
Customize data preprocessing and dataloader pipeline for test set#
test_pipeline = [ dict(type='LoadImageFromFile'), dict(type='Resize', scale=224), dict(type='PackInputs'), ]
Customize data preprocessing and dataloader pipeline for validation set#
val_cfg = dict() val_dataloader = dict( dataset=dict( type=dataset_type, data_root=data_root, ann_file='', data_prefix='val', with_label=True, pipeline=test_pipeline, ), num_workers=8, batch_size=32, sampler=dict(type='DefaultSampler', shuffle=True) )
val_evaluator = dict(topk=(1, 3,), type='Accuracy')
test_dataloader = val_dataloader test_evaluator = val_evaluator
```
Start training#
bash
cd ~/mmpretrain
python tools/train.py configs/mobilenet_v2/mobilenet-v2_8xb32_custom.py
Training logs and weights will be saved in the work_dirs/mobilenet-v2_8xb32_custom folder.
Convert PyTorch model to ONNX model#
Install mmdeploy#
The 'mmdeploy' toolset is designed for deploying your trained model onto various target devices. With its capabilities, you can seamlessly convert PyTorch models into the ONNX format.
```bash
Activate your conda environment#
conda activate tl-classifier
Install mmenigne and mmcv#
mim install mmengine mim install "mmcv>=2.0.0rc2"
Install mmdeploy#
pip install mmdeploy==1.2.0
Support onnxruntime#
pip install mmdeploy-runtime==1.2.0 pip install mmdeploy-runtime-gpu==1.2.0 pip install onnxruntime-gpu==1.8.1
Clone mmdeploy repository#
cd ~/ git clone -b main https://github.com/open-mmlab/mmdeploy.git ```
Convert PyTorch model to ONNX model#
```bash cd ~/mmdeploy
Run deploy.py script#
deploy.py script takes 5 main arguments with these order; config file path, train config file path,#
checkpoint file path, demo image path, and work directory path#
python tools/deploy.py \ ~/mmdeploy/configs/mmpretrain/classification_onnxruntime_static.py\ ~/mmpretrain/configs/mobilenet_v2/train_mobilenet_v2.py \ ~/mmpretrain/work_dirs/train_mobilenet_v2/epoch_300.pth \ /SAMPLE/IAMGE/DIRECTORY \ --work-dir mmdeploy_model/mobilenet_v2 ```
Converted ONNX model will be saved in the mmdeploy/mmdeploy_model/mobilenet_v2 folder.
After obtaining your onnx model, update parameters defined in the launch file (e.g. model_file_path, label_file_path, input_h, input_w...).
Note that, we only support labels defined in tier4_perception_msgs::msg::TrafficLightElement.
Assumptions / Known limits#
(Optional) Error detection and handling#
(Optional) Performance characterization#
References/External links#
[1] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov and L. Chen, "MobileNetV2: Inverted Residuals and Linear Bottlenecks," 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, 2018, pp. 4510-4520, doi: 10.1109/CVPR.2018.00474.
[2] Tan, Mingxing, and Quoc Le. "EfficientNet: Rethinking model scaling for convolutional neural networks." International conference on machine learning. PMLR, 2019.