pointcloud_preprocessor#
Purpose#
The pointcloud_preprocessor is a package that includes the following filters:
- removing outlier points
- cropping
- concatenating pointclouds
- correcting distortion
- downsampling
Inner-workings / Algorithms#
Detail description of each filter's algorithm is in the following links.
| Filter Name | Description | Detail |
|---|---|---|
| concatenate_data | subscribe multiple pointclouds and concatenate them into a pointcloud | link |
| crop_box_filter | remove points within a given box | link |
| distortion_corrector | compensate pointcloud distortion caused by ego vehicle's movement during 1 scan | link |
| downsample_filter | downsampling input pointcloud | link |
| outlier_filter | remove points caused by hardware problems, rain drops and small insects as a noise | link |
| passthrough_filter | remove points on the outside of a range in given field (e.g. x, y, z, intensity) | link |
| pointcloud_accumulator | accumulate pointclouds for a given amount of time | link |
| vector_map_filter | remove points on the outside of lane by using vector map | link |
| vector_map_inside_area_filter | remove points inside of vector map area that has given type by parameter | link |
Inputs / Outputs#
Input#
| Name | Type | Description |
|---|---|---|
~/input/points |
sensor_msgs::msg::PointCloud2 |
reference points |
~/input/indices |
pcl_msgs::msg::Indices |
reference indices |
Output#
| Name | Type | Description |
|---|---|---|
~/output/points |
sensor_msgs::msg::PointCloud2 |
filtered points |
Parameters#
Node Parameters#
| Name | Type | Default Value | Description |
|---|---|---|---|
input_frame |
string | " " | input frame id |
output_frame |
string | " " | output frame id |
max_queue_size |
int | 5 | max queue size of input/output topics |
use_indices |
bool | false | flag to use pointcloud indices |
latched_indices |
bool | false | flag to latch pointcloud indices |
approximate_sync |
bool | false | flag to use approximate sync option |
Assumptions / Known limits#
pointcloud_preprocessor::Filter is implemented based on pcl_perception [1] because
of this issue.
Measuring the performance#
In Autoware, point cloud data from each LiDAR sensor undergoes preprocessing in the sensing pipeline before being input into the perception pipeline. The preprocessing stages are illustrated in the diagram below:
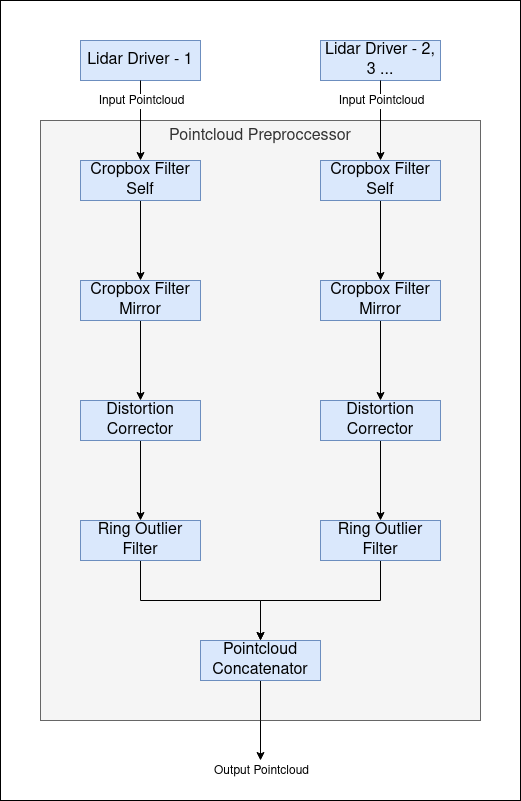
Each stage in the pipeline incurs a processing delay. Mostly, we've used ros2 topic delay /topic_name to measure
the time between the message header and the current time. This approach works well for small-sized messages. However,
when dealing with large point cloud messages, this method introduces an additional delay. This is primarily because
accessing these large point cloud messages externally impacts the pipeline's performance.
Our sensing/perception nodes are designed to run within composable node containers, leveraging intra-process communication. External subscriptions to these messages (like using ros2 topic delay or rviz2) impose extra delays and can even slow down the pipeline by subscribing externally. Therefore, these measurements will not be accurate.
To mitigate this issue, we've adopted a method where each node in the pipeline reports its pipeline latency time. This approach ensures the integrity of intra-process communication and provides a more accurate measure of delays in the pipeline.
Benchmarking The Pipeline#
The nodes within the pipeline report the pipeline latency time, indicating the duration from the sensor driver's pointcloud output to the node's output. This data is crucial for assessing the pipeline's health and efficiency.
When running Autoware, you can monitor the pipeline latency times for each node in the pipeline by subscribing to the following ROS 2 topics:
/sensing/lidar/LidarX/crop_box_filter_self/debug/pipeline_latency_ms/sensing/lidar/LidarX/crop_box_filter_mirror/debug/pipeline_latency_ms/sensing/lidar/LidarX/distortion_corrector/debug/pipeline_latency_ms/sensing/lidar/LidarX/ring_outlier_filter/debug/pipeline_latency_ms/sensing/lidar/concatenate_data_synchronizer/debug/sensing/lidar/LidarX/pointcloud/pipeline_latency_ms
These topics provide the pipeline latency times, giving insights into the delays at various stages of the pipeline from the sensor output of LidarX to each subsequent node.
(Optional) Error detection and handling#
(Optional) Performance characterization#
References/External links#
[1] https://github.com/ros-perception/perception_pcl/blob/ros2/pcl_ros/src/pcl_ros/filters/filter.cpp